Abstract
Cross-modal training using a 2D-3D paired dataset, e.g., multi-view images/scene scans, presents an effective way to
enhance 2D scene understanding by introducing geometric and view-invariance priors into 2D features. However, the need for large-scale scene datasets limits their further im-
provements and scalability. This paper explores an alternative learning method by
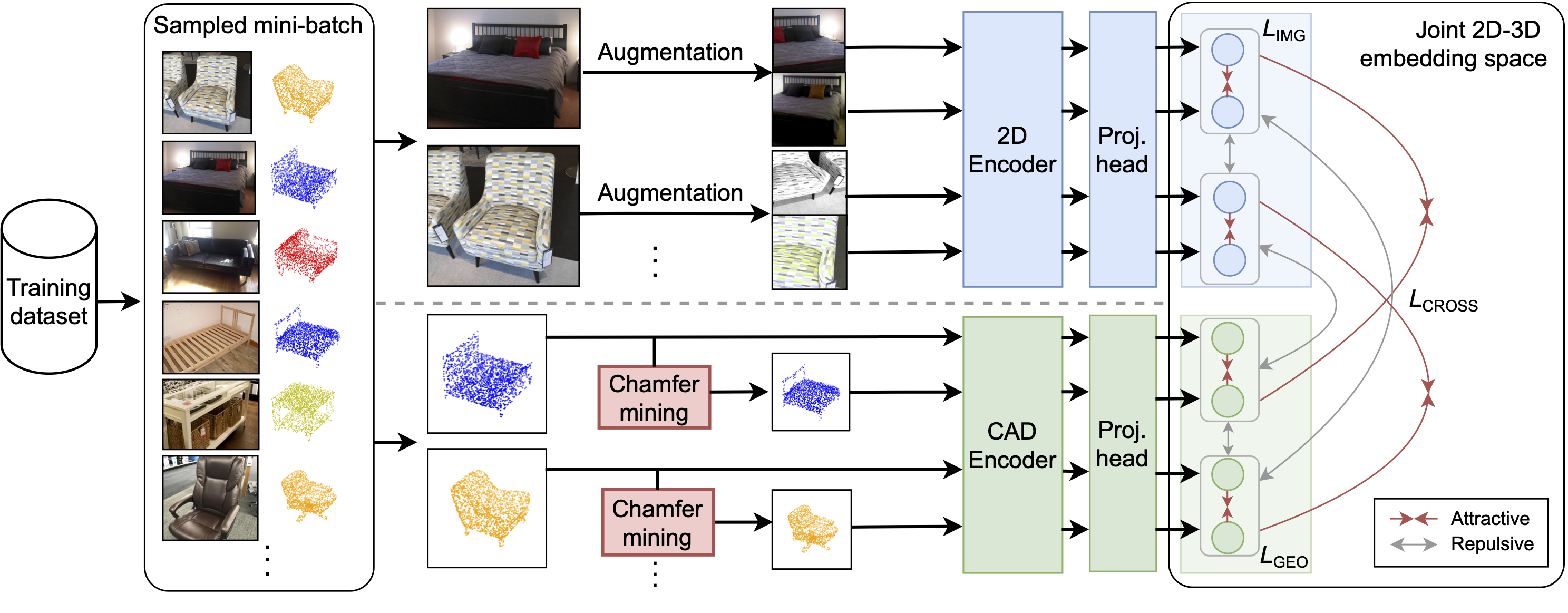
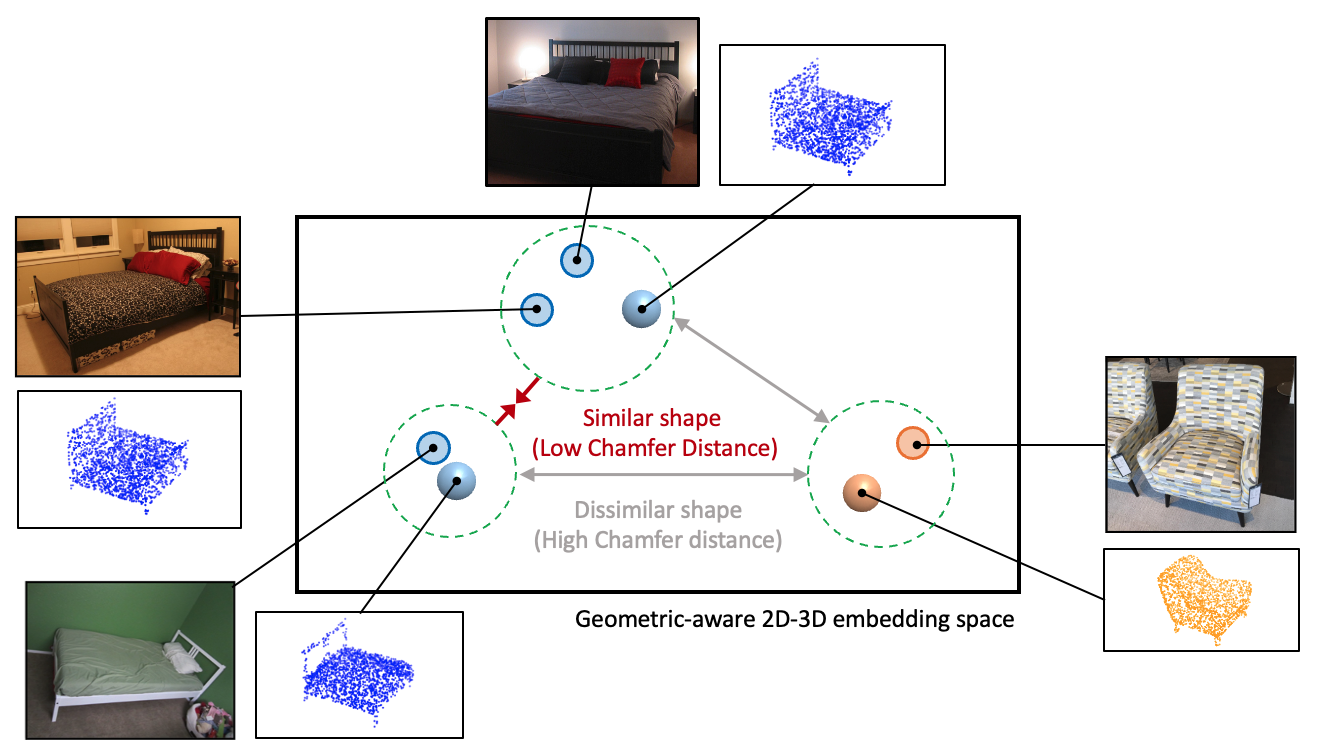
leveraging a lightweight and publicly available type of 3D data, i.e., CAD models. We construct a 3D space with geometric-aware alignment where
the similarity in this space reflects the geometric similarity of CAD models based on the Chamfer distance. The
acquired geometric-aware properties are then induced into
2D features, which boost performance on downstream tasks
more effectively than existing RGB-CAD approaches. Our
technique is not limited to paired RGB-CAD datasets; we
propose an extension for learning such representations on
pseudo pairs generated by existing CAD-based reconstruction methods. By training solely on pseudo pairs, we show
substantial improvement over SOTA 2D pre-trained models
using either ResNet-50 or ViT-B backbone. We also achieve
comparable results to SOTA methods trained on scene scans
on four 2D understanding tasks in NYUv2, SUNRGB-D, indoor ADE20k, and indoor/outdoor COCO, despite using
real or pseudo-generated lightweight CAD models.